CAPTCHA LECTURE
L'opacité et la lisibilité sur le web

Le CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) est une famille de tests automatiques visant à discriminer les humains des ordinateurs dans le but de contrôler l’accès à certains services web. Il s’agit, par un défi-réponse, de vérifier que l’utilisateur n’est pas un robot malveillant dédié par exemple à l’envoi de spams ou à l’extraction automatisée de bases de données.

Les CAPTCHA de Gmail
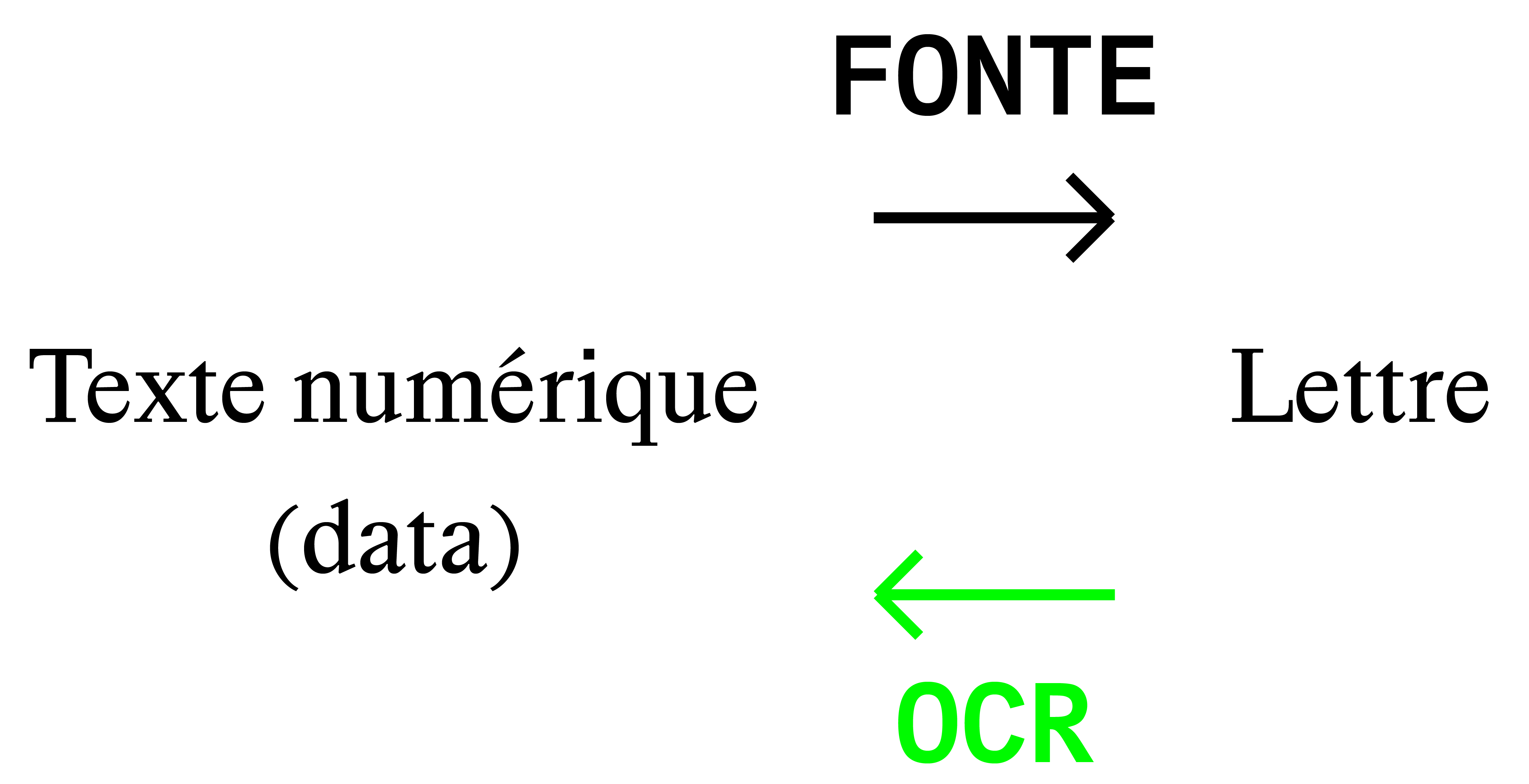
Le CAPTCHA se développe dans le début des année 2000 par les ingénieurs de la Carnegie Mellon University pour contrer les logiciels de reconnaissance de caractères OCR. Pour se faire, l’équipe développeuse du CAPTCHA étudie le manuel de son numériseur et prend le contre-pied de toutes les recommandations données pour améliorer les performances de son système de reconnaissance de caractères. L’équipe conçoit des images casse-têtes utilisant des polices d’écritures disparates, des fonds hétérogènes, des déformations… Les ingénieurs inventent de multiples exemples, dont les premiers sont largement utilisés par Yahoo!

Ce CAPTCHA de «smwm» rend difficile son interprétation par un ordinateur, en modifiant la forme des lettres et en ajoutant un dégradé de couleur en fond. Ces procédés peuvent cependant compromettre la reconnaissance des caractères par un humain. Image par Martin sur Wikipédia.
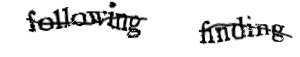
Un exemple de reCAPTCHA datant de 2007: plutôt que d’utiliser un dégradé du fond et une distorsion des lettres, la segmentation est rendue difficile par l’ajout d’une ligne brisée. Image par BMaurer sur Wikipédia.
Une forme de course-poursuite commence alors entre l’amélioration progressive des robots lecteurs et le brouillage des CAPTCHA, entrainant la déformation accrue des caractères, l’usage de couleurs et même le développement de CAPTCHA animés dont les caractères se déforment avec le temps…
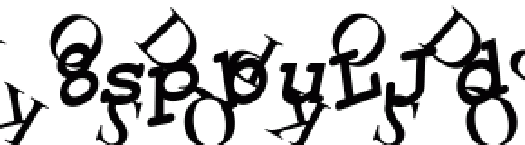
un CAPTCHA animé utilisé par Yahoo!
Le meilleur moyen de contourner l’obstacle qu’il représente, notamment pour mener des campagnes de marketing automatisées, reste de faire appel à des êtres humains. Des sociétés - indiennes principalement, car la main-d’œuvre est très peu chère - se spécialisent dans le décodage des CAPTCHA. Des opérateur·ices les transcrivent en série, jusqu’à plusieurs centaines par heure. Ainsi, ces travailleur·euses à l’autre bout du monde permettent à des robots de se faire passer pour des humains pour mener des campagnes de marketing automatisées.
Très vite, Google met à profit les capacités de reconnaissance que le test mobilise chez les utilisateur·ices humains pour entraîner par la même occasion les intelligences artificielles qu’il développe : c’est le reCAPTCHA. En 2012, les reCAPTCHA consistent en la reconnaissance d’éléments au sein d’images issues de Google Street View pour améliorer la reconnaissance de formes des IA.
Un autre moyen de rendre la segmentation difficile est d’imbriquer les lettres les unes dans les autres, une technique utilisée par Yahoo! pour générer ses CAPTCHA en 2007.
La reconnaissance des CAPTCHA typographiques, quand à elle, s’inscrit dans le projet Google Books, qui numérise les livres du monde entier par brassée. Les caractères numérisés sur des pages froissées ou abimées, difficilement reconnaissables, peuvent alors être déchiffrés grâce aux millions de transcriptions effectuées par les internautes qui entrainent les logiciels de reconnaissance de texte. Ainsi, lorsque l’on transcrit un CAPTCHA, il y a des chances pour que l’on participe à l’amélioration des logiciels de Google. Il y a des chances, donc, que l’on travaille pour Google.
Si l’usage des CAPTCHA typographiques est devenu obsolète sur le web, les formes graphiques qui en ont découlé peuvent être aujourd’hui réinvesties comme outils de contre-surveillance.

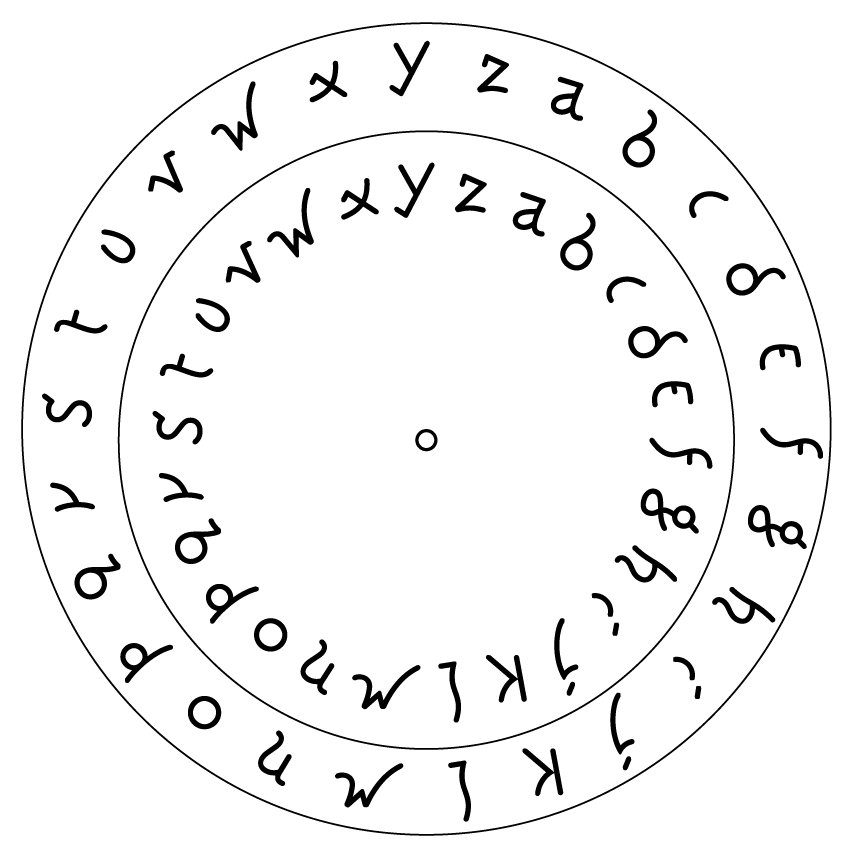
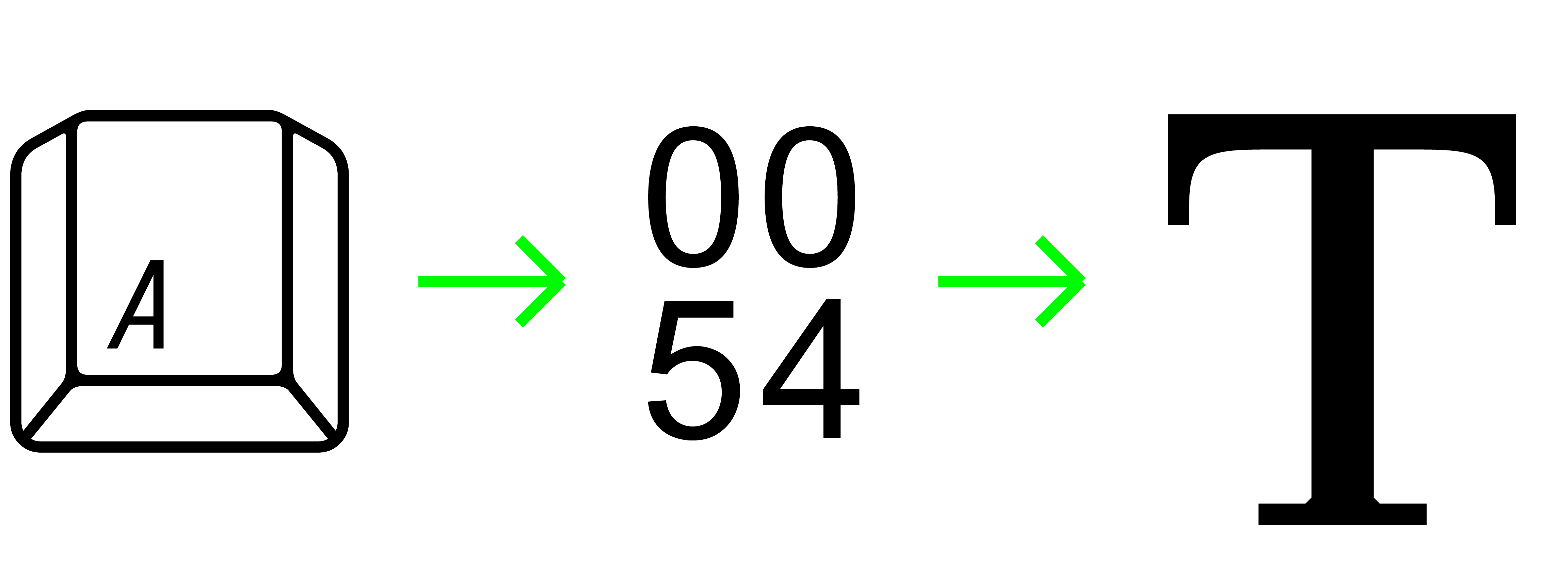
Les CAPTCHA utilisés pour écrire le texte de CAPTCHA LECTURE ont été générés de manière à l’aide de scripts automatisés sur le logiciel Adobe Illustrator. Cette édition s’inscrit dans un projet de recherche sur la lecture du texte par les machines, et les moyens de déjouer celle-ci.
Dans un souci de protection de la vie privée, on pourrait imaginer une police complète qui fonctionnerait comme un CAPTCHA et qui serait illisible pour les OCR ultra-performantes: une telle police devrait être constamment en évolution pour contrer le développement des logiciels de reconnaissance de texte…
Mais au-delà de son efficacité, cette police CAPTCHA proposerait une réponse graphique et symbolique au besoin d’empêcher les ordinateurs de lire tout ce que nous écrivons.